
出處:https://www.ithome.com.tw/news/163730
今日(7/1),長春集團、和碩聯合科技、長庚醫院、欣興電子、科技報橘和專攻法律AI的律果科技,與臺大資工系、臺大資管系就聯手揭露臺灣繁中大型語言模型(LLM)計畫TAiwan Mixture of Experts(簡稱Project TAME),以70億參數的開源模型Llama-3 70B為基礎,使用5,000億個Token和Nvidia開發者計畫技術訓練而成,具備石化、電子製造、醫療、媒體內容和法律等在地專業知識。Project TAME目前於GitHub上開源,團隊希望藉此拋磚引玉、吸引更多產業夥伴加入,來形塑臺灣產業專用AI應用生態系。
今年初發起計畫,3階段打造這款繁中LLM
早在今年1月,這些參與者就發起Project TAME,要打造繁中LLM。目前坊間雖有不少強大的LLM,如GPT系列、Claude系列、Llama系列模型等,但Project TAME主要開發者臺大資工系博士班候選人林彥廷表示,對本土企業和組織而言,仍需要表現穩定的繁中LLM才行。
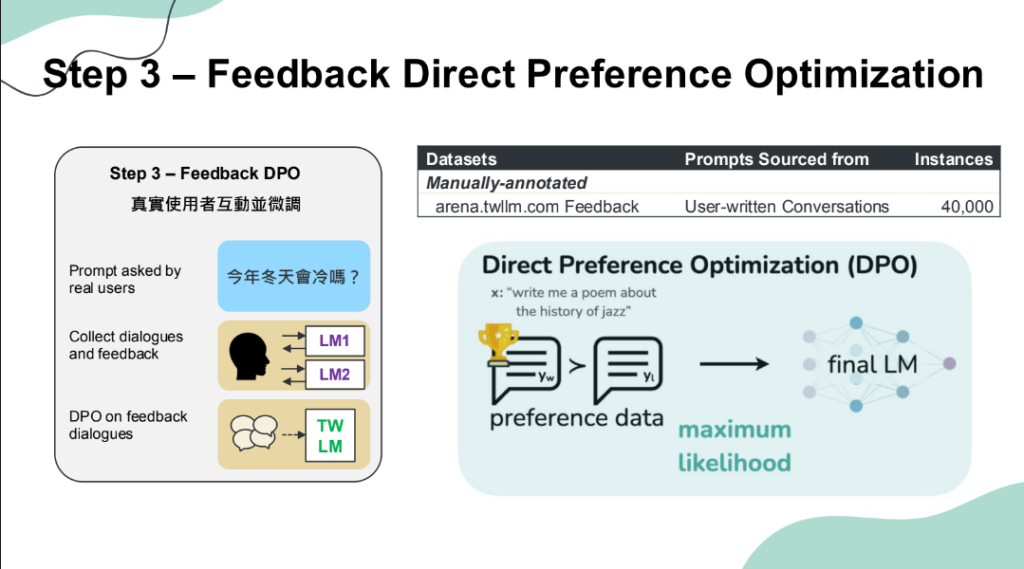
於是,這些本土企業聯手臺大,要打造這個繁中優化的模型TAME。該模型經3大階段訓練而成,包括利用臺灣本土資料進行連續預訓練,再來是生成多輪AI對話資料、進行微調,最後是模型與使用者真實互動,透過使用者回饋來微調模型。
但光是第一階段,團隊就面臨2大難題:本土訓練資料來源,以及各領域專家確認資料來源與品質。為解決這個問題,他們採用聚集各領域專家、提供相關資料的模式,來因應資料不足的挑戰。而這些資料來源,包括了占所有訓練資料三分之一的合成資料(如合成教科書內容等),約1,000億Token左右,以及其他來自媒體、石化、法律、醫療、化工、製造業製程、遊戲等資料,包括來自網頁、社群平臺、資料庫、書籍、程式碼等。(如下圖)

接著,在技術部分,團隊訓練的基礎模型有兩種,包括Meta的80億參數模型Llama-3 8B和700億參數Llama-3 70B,採用Nvidia NeMo、Nvidia NeMo Megatron兩種訓練框架,以及3D平行化、DeepSpeed Zero網路通訊優化器和Flash Attention等加速方法與工具,來訓練TAME模型。在推論部分,他們採用Nvidia TensorRT-LLM框架執行,另使用Nvidia建置的Taipei-1超級電腦(搭載DGX H100)算力來驅動模型訓練與推論。
讓模型飽讀詩書、具備繁中基礎知識後,接下來就進入第二階段:監督式微調。在這階段,首先會從資料中取出提示,模型會根據提示來自我對話、生成多輪對話,最後根據這些對話資料來進行監督式微調。這些對話資料涵蓋了通用型和知識密集型資料。
完成對話微調後,再來就是最後一階段,也就是透過模型與真人互動,來根據人類回饋微調模型,確保模型產出與人類偏好一致。為此,團隊也繁中LLM競技場添加TAME,讓民眾在平臺上提問,並根據2個模型給出的回答,來評估模型表現。透過這種方式,就能進一步改善TAME模型的不足之處。
在地文化理解力、專業知識能力實測皆第一
完成3階段的訓練後,接著,團隊利用標準化測試題目,來評估Project TAME模型表現。
首先是包含各種本土考試科目的語義理解基準測試TMLU,不只有國高中文科、數理化等考題,還有教師資格、領隊、駕駛等考題。經測試,Project TAME的平均分數為71.3%,與Claude 3的73.6相差無幾,還勝過GPT-4、Gemini、Llama 3等模型。
… 其他內容詳見原文:https://www.ithome.com.tw/news/163730